挑戰
隨著數據量的快速增長,越來越多的企業迎來業務數據化時代,數據成為了最重要的生產資料和業務升級依據。伴隨著業務對海量數據實時分析的需求越來越多,數據分析技術這兩年也迎來了一些新的挑戰和變革:
在線化和高可用,離線和在線的邊界越來越模糊,一切數據皆服務化、一切分析皆在線化。
高并發低延時,越來越多的數據系統直接服務終端客戶,對系統的并發和處理延時提出了新的交互性挑戰。
混合負載, 一套實時分析系統既要支持數據加工處理,又要支持高并發低延時的交互式查詢。
融合分析, 隨著對數據新的使用方式探索,需要解決結構化與非結構化數據融合場景下的數據檢索和分析問題。
阿里巴巴最初通過單節點 Oracle 進行準實時分析, 后來轉到 Oracle RAC,隨著業務的飛速發展, 集中式的 Shared Storage 架構需要快速轉向分布式,遷移到了 Greenplum,但不到一年時間便遇到擴展性和并發的嚴重瓶頸。為了迎接更大數據集、更高并發、更高可用、更實時的數據應用發展趨勢,從 2011 年開始,在線分析這個技術領域,阿里實時數倉堅定的走上了自研之路。
分析型數據庫 AnalyticDB
AnalyticDB 是阿里巴巴自主研發、唯一經過超大規模以及核心業務驗證的 PB 級實時數據倉庫。自 2012 年第一次在集團發布上線以來,至今已累計迭代發布近百個版本,支撐起集團內的電商、廣告、菜鳥、文娛、飛豬等眾多在線分析業務。
AnalyticDB 于 2014 年在阿里云開始正式對外輸出,支撐行業既包括傳統的大中型企業和政府機構,也包括眾多的互聯網公司,覆蓋外部十幾個行業。AnalyticDB 承接著阿里巴巴廣告營銷、商家數據服務、菜鳥物流、盒馬新零售等眾多核心業務的高并發分析處理, 每年雙十一上述眾多實時分析業務高峰驅動著 AnalyticDB 不斷的架構演進和技術創新。
經過這 2 年的演進和創新,AnalyticDB 已經成長為兼容 MySQL 5.x 系列、并在此基礎上增強支持 ANSI SQL:2003 的 OLAP 標準(如 window function)的通用實時數倉,躋身為實時數倉領域極具行業競爭力的產品。近期,AnalyticDB 成功入選了全球權威 IT 咨詢機構 Forrester 發布 “The Forrester Wave?: CloudData Warehouse,Q4 2018” 研究報告的 Contenders 象限,以及 Gartner 發布的分析型數據管理平臺報告 (Magic Quadrant forData Management Solutions for Analytics),開始進入全球分析市場。AnalyticDB 旨在幫客戶將整個數據分析和價值化從傳統的離線分析帶到下一代的在線實時分析模式。
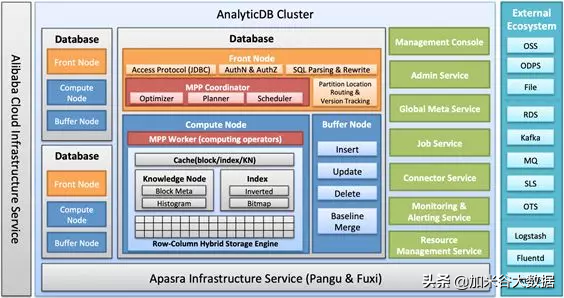
整體架構
經過過去 2 年的架構演進和功能迭代,AnalyticDB 當前整體架構如下圖。
AnalyticDB 是一個支持多租戶的 Cloud Native Realtime Data Warehouse 平臺,每個租戶 DB 的資源隔離,每個 DB 都有相應獨立的模塊(圖中的 Front Node, Compute Node, Buffer Node),在處理實時寫入和查詢時,這些模塊都是資源 (CPU, Memory) 使用密集型的服務,需要進行 DB 間隔離保證服務質量。同時從功能完整性和成本優化層面考慮,又有一系列集群級別服務(圖中綠色部分模塊)。
下面是對每個模塊的具體描述:
DB 級別服務組件:
Front Node:負責 JDBC, ODBC 協議層接入,認證和鑒權,SQL 解析、重寫;分區地址路由和版本管理;同時優化器,執行計劃和 MPP 計算的調度模塊也在 Front Node。
Compute Node: 包含 MPP 計算 Worker 模塊,和存儲模塊(行列混存,元數據,索引)。
Buffer Node: 負責實時寫入,并根據實時數據大小觸發索引構建和合并。
集群級別服務組件:
Management Console: 管理控制臺。
Admin Service:集群管控服務,負責計量計費,實例生命周期管理等商業化功能,同時提供 OpenAPI 和 InnerAPI 給 Management Console 和第三方調用。
Global Meta Service:全局元數據管理,提供每個 DB 的元數據管理服務,同時提供分區分配,副本管理,版本管理,分布式 DDL 等能力。
Job Service:作業服務,提供異步作業調度能力。異步作業包括索引構建、擴容、無縫升級、刪庫刪表的后臺異步數據清理等。
Connector Service:數據源連接服務,負責外部各數據源(圖中右側部分)接入到 AnalyticDB。目前該服務開發基本完成,即將上線提供云服務。
Monitoring & Alerting Service:監控告警診斷服務,既提供面向內部人員的運維監控告警診斷平臺,又作為數據源通過 Management Console 面向用戶側提供數據庫監控服務。
Resource Management Service:資源管理服務,負責集群級別和 DB 級別服務的創建、刪除、DNS/SLB 掛載 / 卸載、擴縮容、升降配,無縫升級、服務發現、服務健康檢查與恢復。
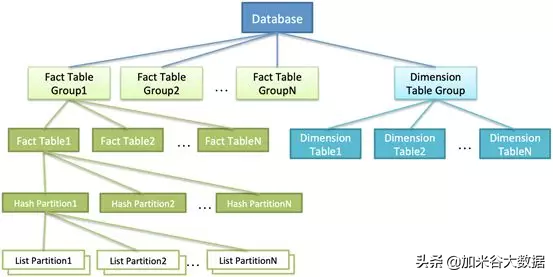
數據模型
AnalyticDB 中表組 (Table Group) 分為兩類:事實表組和維度表組。
事實表組 (Fact Table Group),表組在 AnalyticDB 里是一個邏輯概念,用戶可以將業務上關聯性比較多的事實表放在同一個事實表組下,主要是為了方便客戶做眾多數據業務表的管理,同時還可以加速 Co-location Join 計算。
維度表組 (Dimension Table Group),用于存放維度表,目前有且僅有一個,在數據庫建立時會自動創建,維度表特征上是一種數據量較小但是需要和事實表進行潛在關聯的表。
AnalyticDB 中表分為事實表 (Fact Table) 和維度表 (Dimension Table)。
事實表創建時至少要指定 Hash 分區列和相關分區信息,并且指定存放在一個表組中,同時支持 List 二級分區。
Hash Partition 將數據按照分區列進行 hash 分區,hash 分區被分布到多個 Compute Node 中。
List Partition(如果指定 List 分區列的話) 對一個 hash 分區進行再分區,一般按照時間 (如每天一個 list 分區)。
一個 Hash Partition 的所有 List Partition 默認存放于同一個 Compute Node 中。每個 Hash Partition 配有多個副本(通常為雙副本),分布在不同的 Compute Node 中,做到高可用和高并發。
維度表可以和任意表組的任意表進行關聯,并且創建時不需要配置分區信息,但是對單表數據量大小有所限制,并且需要消耗更多的存儲資源,會被存儲在每個屬于該 DB 的 Compute Node 中。
下圖描述了從 Database 到 List 分區到數據模型:
對于 Compute Node 來說,事實表的每個 List 分區是一個物理存儲單元(如果沒有指定 List 分區列,可認為該 Hash 分區只有一個 List 分區)。一個分區物理存儲單元采用行列混存模式,配合元數據和索引,提供高效查詢。
海量數據
基于上述數據模型,AnalyticDB 提供了單庫 PB 級數據實時分析能力。以下是生產環境的真實數據:
阿里巴巴集團某營銷應用單 DB 表數超過 20000 張
云上某企業客戶單 DB 數據量近 3PB,單日分析查詢次數超過 1 億
阿里巴巴集團內某單個 AnalyticDB 集群超過 2000 臺節點規模
云上某業務實時寫入壓力高達 1000w TPS
菜鳥網絡某數據業務極度復雜分析場景,查詢 QPS 100+
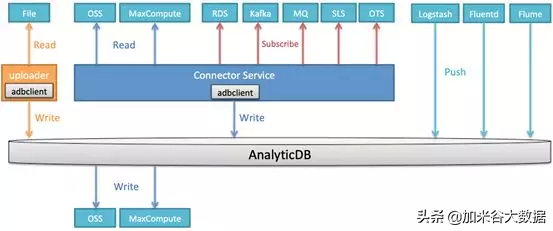
導入導出
靈活的數據導入導出能力對一個實時數倉來說至關重要,AnalyticDB 當前既支持通過阿里云數據傳輸服務 DTS、DataWorks 數據集成從各種外部數據源導入入庫,同時也在不斷完善自身的數據導入能力。整體導入導出能力如下圖(其中導入部分數據源當前已支持,部分在開發中,即將發布)。
★ 數據導入
首先,由于 AnalyticDB 兼容 MySQL5.x 系列,支持通過 MySQL JDBC 方式把數據 insert 入庫。為了獲得最佳寫入性能,AnalyticDB 提供了 Client SDK,實現分區聚合寫的優化,相比通過 JDBC 單條 insert,寫入性能有 10 倍以上提升。對于應用端業務邏輯需要直接寫入 AnalyticDB 的場景,推薦使用 AnalyticDB Client SDK。
同時,對于快速上傳本地結構化的文本文件,可以使用基于 AnalyticDB Client SDK 開發的 Uploader 工具。對于特別大的文件,可以拆分后使用 uploader 工具進行并行導入。
另外,對于 OSS,MaxCompute 這樣的外部數據源,AnalyticDB 通過分布式的 Connector Service 數據導入服務并發讀取并寫入到相應 DB 中。Connector Service 還將支持訂閱模式,從 Kafka,MQ,RDS 等動態數據源把數據導入到相應 DB 中。AnalyticDB 對大數據生態的 Logstash,Fluentd,Flume 等日志收集端、ETL 工具等通過相應插件支持,能夠快速把數據寫入相應 DB。
今天在阿里巴巴集團內,每天有數萬張表從 MaxCompute 導入到 AnalyticDB 中進行在線分析,其中大量導入任務單表數據大小在 TB 級、數據量近千億。
★ 數據導出
AnalyticDB 目前支持數據導出到 OSS 和 MaxCompute,業務場景主要是把相應查詢結果在外部存儲進行保存歸檔,實現原理類似 insert from select 操作。insert from select 是把查詢結果寫入到內部表,而導出操作則是寫入外部存儲, 通過改進實現機制,可以方便地支持更多的導出數據源。
核心技術
高性能 SQL Parser
AnalyticDB 經過數年的發展,語法解析器也經歷了多次更新迭代。曾經使用過業界主流的 Antlr( http://www.antlr.org ),JavaCC( https://javacc.org ) 等 Parser 生成器作為 SQL 語法解析器,但是兩者在長期、大規模、復雜查詢場景下,Parser 的性能、語法兼容、API 設計等方面不滿足要求,于是我們引入了自研的 SQL Parser 組件 FastSQL。
★ 領先業界的 Parser 性能
AnalyticDB 主打的場景是高并發、低延時的在線化分析,對 SQL Parser 性能要求很高,批量實時寫入等場景要求更加苛刻。FastSQL 通過多種技術優化提升 Parser 性能,例如:
快速對比:使用 64 位 hash 算法加速關鍵字匹配,使用 fnv_1a_64 hash 算法,在讀取 identifier 的同時計算好 hash 值,并利用 hash64 低碰撞概率的特點,使用 64 位 hash code 直接比較,比常規 Lexer 先讀取 identifier,在查找 SymbolTable 速度更快。
高性能的數值 Parser:Java 自帶的 Integer.parseInt()/Float.parseFloat() 需要構造字符串再做 parse,FastSQL 改進后可以直接在原文本上邊讀取邊計算數值。
分支預測:在 insert values 中,出現常量字面值的概率比出現其他的 token 要高得多,通過分支預測可以減少判斷提升性能。
以 TPC-DS99 個 Query 對比來看,FastSQL 比 Antlr Parser(使用 Antlr 生成)平均快 20 倍,比 JSQLParser(使用 JavaCC 生成)平均快 30 倍,在批量 Insert 場景、多列查詢場景下,使用 FastSQL 后速度提升 30~50 倍。
★ 無縫結合優化器
在結合 AnalyticDB 的優化器的 SQL 優化實踐中,FastSQL 不斷將 SQL Rewrite 的優化能力前置化到 SQL Parser 中實現,通過與優化器的 SQL 優化能力協商,將盡可能多的表達式級別優化前置化到 SQL Parser 中,使得優化器能更加專注于基于代價和成本的優化(CBO,Cost-Based Optimization)上,讓優化器能更多的集中在理解計算執行計劃優化上。FastSQL 在 AST Tree 上實現了許多 SQL Rewrite 的能力,例如:
玄武存儲引擎
為保證大吞吐寫入,以及高并發低時延響應,AnalyticDB 自研存儲引擎玄武,采用多項創新的技術架構。玄武存儲引擎采用讀 / 寫實例分離架構,讀節點和寫節點可分別獨立擴展,提供寫入吞吐或者查詢計算能力。在此架構下大吞吐數據寫入不影響查詢分析性能。同時玄武存儲引擎構筑了智能全索引體系,保證絕大部分計算基于索引完成,保證任意組合條件查詢的毫秒級響應。
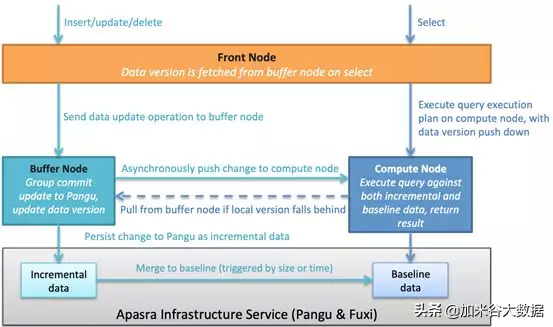
★ 讀寫分離架構支持大吞吐寫入
傳統數據倉庫并沒有將讀和寫分開處理,即這些數據庫進程 / 線程處理請求的時候,不管讀寫都會在同一個實例的處理鏈路上進行。因此所有的請求都共享同一份資源(內存資源、鎖資源、IO 資源),并相互影響。在查詢請求和寫入吞吐都很高的時候,會存在嚴重的資源競爭,導致查詢性能和寫入吞吐都下降。
為了解決這個問題,玄武存儲引擎設計了讀寫分離的架構。如下圖所示,玄武存儲引擎有兩類關鍵的節點:Buffer Node 和 Compute Node。Buffer Node 專門負責處理寫請求,Compute Node 專門負責查詢請求,Buffer Node 和 Compute Node 完全獨立并互相不影響,因此,讀寫請求會在兩個完全不相同的鏈路中處理。上層的 Front Node 會把讀寫請求分別路由給 Buffer Node 和 Compute Node。
實時寫入鏈路:
業務實時數據通過 JDBC/ODBC 協議寫入到 Front Node。
Front Node 根據實時數據的 hash 分區列值,路由到相應 Buffer Node。
Buffer Node 將該實時數據的內容(類似于 WAL)提交到盤古分布式文件系統,同時更新實時數據版本,并返回 Front Node,Front Node 返回寫入成功響應到客戶端。
Buffer Node 同時會異步地把實時數據內容推送到 Compute Node,Compute Node 消費該實時數據并構建實時數據輕量級索引。
當實時數據積攢到一定量時,Buffer Node 觸發后臺 Merge Baseline 作業,對實時數據構建完全索引并與基線數據合并。
實時查詢鏈路:
業務實時查詢請求通過 JDBC/ODBC 協議發送到 Front Node。
Front Node 首先從 Buffer Node 拿到當前最新的實時數據版本,并把該版本隨執行計劃一起下發到 Compute Node。
Compute Node 檢查本地實時數據版本是否滿足實時查詢要求,若滿足,則直接執行并返回數據。若不滿足,需先到 Buffer Node 把指定版本的實時數據拖到本地,再執行查詢,以保證查詢的實時性(強一致)。
AnalyticDB 提供強實時和弱實時兩種模式,強實時模式執行邏輯描述如上。弱實時模式下,Front Node 查詢請求則不帶版本下發,返回結果的實時取決于 Compute Node 對實時數據的處理速度,一般有秒極延遲。所以強實時在保證數據一致性的前提下,當實時數據寫入量比較大時對查詢性能會有一定的影響。
高可靠性
玄武存儲引擎為 Buffer Node 和 Compute Node 提供了高可靠機制。用戶可以定義 Buffer Node 和 Compute Node 的副本數目(默認為 2),玄武保證同一個數據分區的不同副本一定是存放在不同的物理機器上。Compute Node 的組成采用了對等的熱副本服務機制,所有 Compute Node 節點都可以參與計算。另外,Computed Node 的正常運行并不會受到 Buffer Node 節點異常的影響。如果 Buffer Node 節點異常導致 Compute Node 無法正常拉取最新版本的數據,Compute Node 會直接從盤古上獲取數據(即便這樣需要忍受更高的延遲)來保證查詢的正常執行。數據在 Compute Node 上也是備份存儲。如下圖所示,數據是通過分區存放在不同的 ComputeNode 上,具有相同 hash 值的分區會存儲在同一個 Compute Node 上。數據分區的副本會存儲在其他不同的 Compute Node 上,以提供高可靠性。
高擴展性
玄武的兩個重要特性設計保證了其高可擴展性:1)Compute Node 和 Buffer Node 都是無狀態的,他們可以根據業務負載需求進行任意的增減;2)玄武并不實際存儲數據,而是將數據存到底層的盤古系統中,這樣,當 Compute Node 和 Buffer Node 的數量進行改變時,并不需要進行實際的數據遷移工作。
★ 為計算而生的存儲
數據存儲格式
傳統關系型數據庫一般采用行存儲 (Row-oriented Storage) 加 B-tree 索引,優勢在于其讀取多列或所有列 (SELECT *) 場景下的性能,典型的例子如 MySQL 的 InnoDB 引擎。但是在讀取單列、少數列并且行數很多的場景下,行存儲會存在嚴重的讀放大問題。
數據倉庫系統一般采用列存儲 (Column-oriented Storage),優勢在于其單列或少數列查詢場景下的性能、更高的壓縮率 (很多時候一個列的數據具有相似性,并且根據不同列的值類型可以采用不同的壓縮算法)、列聚合計算 (SUM, AVG, MAX, etc.) 場景下的性能。但是如果用戶想要讀取整行的數據,列存儲會帶來大量的隨機 IO,影響系統性能。
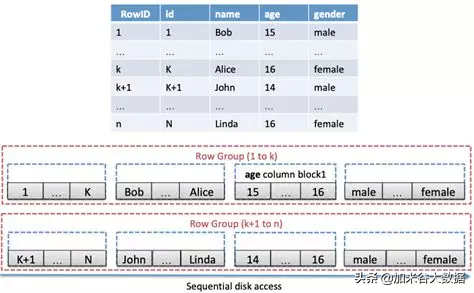
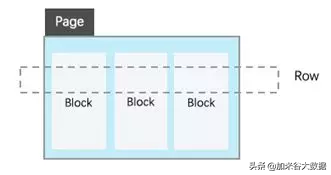
為了發揮行存儲和列存儲各自的優勢,同時避免兩者的缺點,AnalyticDB 設計并實現了全新的行列混存模式。如下圖所示:
對于一張表,每 k 行數據組成一個 Row Group。在每個 Row Group 中,每列數據連續的存放在單獨的 block 中,每 Row Group 在磁盤上連續存放。
Row Group 內列 block 的數據可按指定列 (聚集列) 排序存放,好處是在按該列查詢時顯著減少磁盤隨機 IO 次數。
每個列 block 可開啟壓縮。
行列混存存儲相應的元數據包括:分區元數據,列元數據,列 block 元數據。其中分區元數據包含該分區總行數,單個 block 中的列行數等信息;列元數據包括該列值類型、整列的 MAX/MIN 值、NULL 值數目、直方圖信息等,用于加速查詢;列 block 元數據包含該列在單個 Row Group 中對應的 MAX/MIN/SUM、總條目數 (COUNT) 等信息,同樣用于加速查詢。
全索引計算
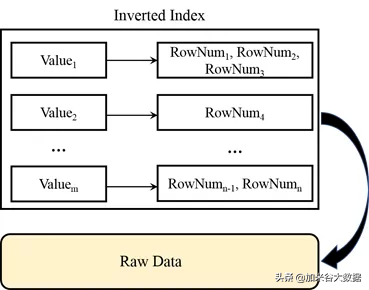
用戶的復雜查詢可能會涉及到各種不同的列,為了保證用戶的復雜查詢能夠得到秒級響應,玄武存儲引擎在行列混合存儲的基礎上,為基線數據(即歷史數據)所有列都構建了索引。玄武會根據列的數據特征和空間消耗情況自動選擇構建倒排索引、位圖索引或區間樹索引等,而用的最多的是倒排索引。
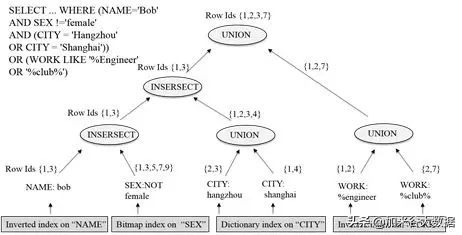
如上圖所示,在倒排索引中,每列的數值對應索引的 key,該數值對應的行號對應索引的 value,同時所有索引的 key 都會進行排序。依靠全列索引,交集、并集、差集等數據庫基礎操作可以高性能地完成。如下圖所示,用戶的一個復雜查詢包含著對任意列的條件篩選。玄武會根據每個列的條件,去索引中篩選滿足條件的行號,然后再將每列篩選出的行號,進行交、并、差操作,篩選出最終滿足所有條件的行號。玄武會依據這些行號去訪問實際的數據,并返回給用戶。通常經過篩選后,滿足條件的行數可能只占總行數的萬分之一到十萬分之一。因此,全列索引幫助玄武在執行查詢請求的時候,大大減小需要實際遍歷的行數,進而大幅提升查詢性能,滿足任意復雜查詢秒級響應的需求。
使用全列索引給設計帶來了一個很大挑戰:需要對大量數據構建索引,這會是一個非常耗時的過程。如果像傳統數據庫那樣在數據寫入的路徑上進行索引構建,那么這會嚴重影響寫入的吞吐,而且會嚴重拖慢查詢的性能,影響用戶體驗。為了解決這個挑戰,玄武采用了異步構建索引的方式。當寫入請求到達后,玄武把寫 SQL 持久化到盤古,然后直接返回,并不進行索引的構建。
當這些未構建索引的數據(稱為實時數據)積累到一定數量時,玄武會開啟多個 MapReduce 任務,來對這些實時數據進行索引的構建,并將實時數據及其索引,同當前版本的基線數據(歷史數據)及其索引進行多版本歸并, 形成新版本的基線數據和索引。這些 MapReduce 任務通過伏羲進行分布式調度和執行,異步地完成索引的構建。這種異步構建索引的方式,既不影響 AnalyticDB 的高吞吐寫入,也不影響 AnalyticDB 的高性能查詢。
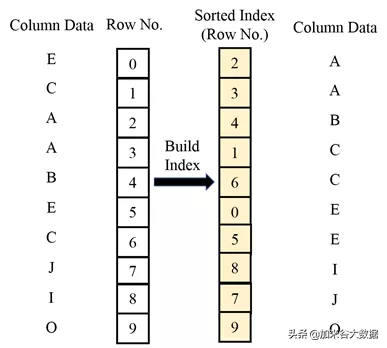
異步構建索引的機制還會引入一個新問題:在進行 MapReduce 構建索引的任務之前,新寫入的實時數據是沒有索引的,如果用戶的查詢會涉及到實時數據,查詢性能有可能會受到影響。玄武采用為實時數據構建排序索引(Sorted Index)的機制來解決這個問題。
如下圖所示,玄武在將實時數據以 block 形式刷到磁盤之前,會根據每一列的實時數據生成對應的排序索引。排序索引實際是一個行號數組,對于升序排序索引來說,行號數組的第一個數值是實時數據最小值對應的行號,第二個數值是實時數據第二小值對應的行號,以此類推。這種情況下,對實時數據的搜索復雜度會從 O(N) 降低為 O(lgN)。排序索引大小通常很小(60KB 左右),因此,排序索引可以緩存在內存中,以加速查詢。
羲和計算引擎
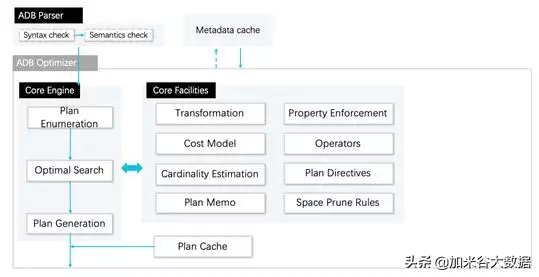
針對低延遲高并發的在線分析場景需求,AnalyticDB 自研了羲和大規模分析引擎,其中包括了基于流水線模型的分布式并行計算引擎,以及基于規則 (Rule-Based Optimizer,RBO) 和代價 (Cost-Based Optimizer,CBO) 的智能查詢優化器。
★ 優化器
優化規則的豐富程度是能否產生最優計劃的一個重要指標。因為只有可選方案足夠多時,才有可能選到最優的執行計劃。AnalyticDB 提供了豐富的關系代數轉換規則,用來確保不會遺漏最優計劃。
基礎優化規則:
裁剪規則:列裁剪、分區裁剪、子查詢裁剪
下推/合并規則:謂詞下推、函數下推、聚合下推、Limit 下推
去重規則:Project 去重、Exchange 去重、Sort 去重
常量折疊/謂詞推導
探測優化規則:
Joins:BroadcastHashJoin、RedistributedHashJoin、NestLoopIndexJoin
Aggregate:HashAggregate、SingleAggregate
JoinReordering
GroupBy 下推、Exchange 下推、Sort 下推
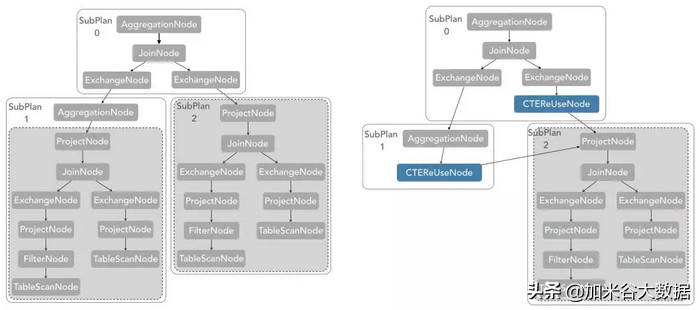
高級優化規則:CTE
例如下圖中,CTE 的優化規則的實現將兩部分相同的執行邏輯合為一個。通過類似于最長公共子序列的算法,對整個執行計劃進行遍歷,并對一些可以忽略的算子進行特殊處理,如 Projection,最終達到減少計算的目的。
單純基于規則的優化器往往過于依賴規則的順序,同樣的規則不同的順序會導致生成的計劃完全不同,結合基于代價的優化器則可以通過嘗試各種可能的執行計劃,達到全局最優。
AnalyticDB 的代價優化器基于 Cascade 模型,執行計劃經過 Transform 模塊進行了等價關系代數變換,對可能的等價執行計劃,估算出按 Cost Model 量化的計劃代價,并從中最終選擇出代價最小的執行計劃通過 Plan Generation 模塊輸出,存入 Plan Cache(計劃緩存),以降低下一次相同查詢的優化時間。
在線分析的場景對優化器有很高的要求,AnalyticDB 為此開發了三個關鍵特性:存儲感知優化、動態統計信息收集和計劃緩存。
存儲層感知優化
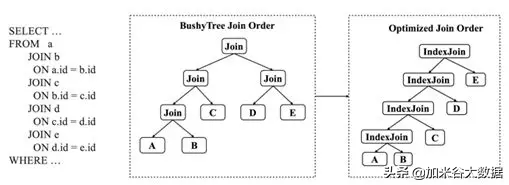
生成分布式執行計劃時,AnalyticDB 優化器可以充分利用底層存儲的特性,特別是在 Join 策略選擇,Join Reorder 和謂詞下推方面。
底層數據的哈希分布策略將會影響 Join 策略的選擇。基于規則的優化器,在生成 Join 的執行計劃時,如果對數據物理分布特性的不感知,會強制增加一個數據重分布的算子來保證其執行語義的正確。 數據重分布帶來的物理開銷非常大,涉及到數據的序列化、反序列化、網絡開銷等等,因此避免多次數據重分布對于分布式計算是非常重要的。除此之外,優化器也會考慮對數據庫索引的使用,進一步減少 Join 過程中構建哈希的開銷。
調整 Join 順序時,如果大多數 Join 是在分區列,優化器將避免生成 Bushy Tree,而更偏向使用 Left Deep Tree,并盡量使用現有索引進行查找。
優化器更近一步下推了謂詞和聚合。聚合函數,比如 count(),和查詢過濾可以直接基于索引計算。
所有這些組合降低了查詢延遲,同時提高集群利用率,從而使得 AnalyticDB 能輕松支持高并發。
動態統計信息收集
統計信息是優化器在做基于代價查詢優化所需的基本信息,通常包括有關表、列和索引等的統計信息。傳統數據倉庫僅收集有限的統計信息,例如列上典型的最常值(MFV)。商業數據庫為用戶提供了收集統計信息的工具,但這通常取決于 DBA 的經驗,依賴 DBA 來決定收集哪些統計數據,并依賴于服務或工具供應商。
上述方法收集的統計數據通常都是靜態的,它可能需要在一段時間后,或者當數據更改達到一定程度,來重新收集。但是,隨著業務應用程序變得越來越復雜和動態,預定義的統計信息收集可能無法以更有針對性的方式幫助查詢。例如,用戶可以選擇不同的聚合列和列數,其組合可能會有很大差異。但是,在查詢生成之前很難預測這樣的組合。因此,很難在統計收集時決定正確統計方案。但是,此類統計信息可幫助優化器做出正確決定。
我們設計了一個查詢驅動的動態統計信息收集機制來解決此問題。守護程序動態監視傳入的查詢工作負載和特點以提取其查詢模式,并基于查詢模式,分析缺失和有益的統計數據。在此分析和預測之上,異步統計信息收集任務在后臺執行。這項工作旨在減少收集不必要的統計數據,同時使大多數即將到來的查詢受益。對于前面提到的聚合示例,收集多列統計信息通常很昂貴,尤其是當用戶表有大量列的時候。根據我們的動態工作負載分析和預測,可以做到僅收集必要的多列統計信息,同時,優化器能夠利用這些統計數據來估計聚合中不同選項的成本并做出正確的決策。
計劃緩存
從在線應用案件看,大多數客戶都有一個共同的特點,他們經常反復提交類似的查詢。在這種情況下,計劃緩存變得至關重要。為了提高緩存命中率,AnalyticDB 不使用原始 SQL 文本作為搜索鍵來緩存。相反,SQL 語句首先通過重寫并參數化來提取模式。例如,查詢 “SELECT * FROM t1 WHERE a = 5 + 5”將轉化為“SELECT * FROM t1 WHERE a =?”。參數化的 SQL 模版將被作為計劃緩存的關鍵字,如果緩存命中,AnalyticDB 將根據新查詢進行參數綁定。由于這個改動,即使使用有限的緩存大小,優化器在生產環境也可以保持高達 90%以上的命中率,而之前只能達到 40%的命中率。
這種方法仍然有一個問題。假設我們在列 a 上有索引,“SELECT * FROM t1 WHERE a = 5”的優化計劃可以將索引掃描作為其最佳訪問路徑。但是,如果新查詢是“SELECT * FROM t1 WHERE a = 0”并且直方圖告訴我們數值 0 在表 t1 占大多數,那么索引掃描可能不如全表掃描有效。在這種情況下,使用緩存中的計劃并不是一個好的決定。為了避免這類問題,AnalyticDB 提供了一個功能 Literal Classification,使用列的直方圖對該列的值進行分類,僅當與模式相關聯的常量“5”的數據分布與新查詢中常量“0”的數據分布類似時,才實際使用高速緩存的計劃。否則,仍會對新查詢執行常規優化。
★ 執行引擎
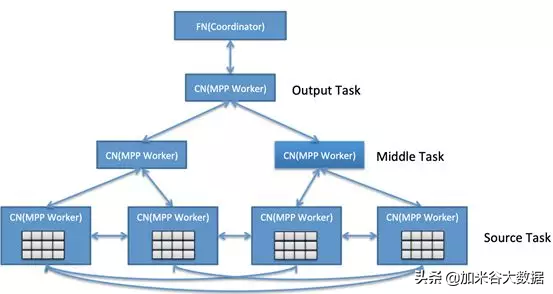
在優化器之下,AnalyticDB 在 MPP 架構基礎上,采用流水線執行的 DAG 架構,構建了一個適用于低延遲和高吞吐量工作負載的執行器。如下圖所示,當涉及到多個表之間非分區列 JOIN 時,CN(MPP Worker) 會先進行 data exchange (shuffling) 然后再本地 JOIN (SourceTask),aggregate 后發送到上一個 stage(MiddleTask),最后匯總到 Output Task。由于絕大多情況都是 in-memory 計算(除復雜 ETL 類查詢,盡量無中間 Stage 落盤)且各個 stage 之間都是 pipeline 方式協作,性能上要比 MapReduce 方式快一個數量級。
在接下來的幾節中,將介紹其中三種特性,包括混合工作負載管理,CodeGen 和矢量化執行。
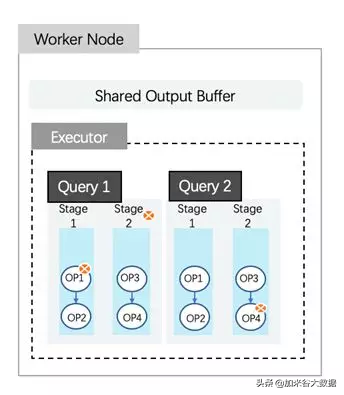
混合工作負載管理
作為一套完備的實時數倉解決方案,AnalyticDB 中既有需要較低響應時間的高并發查詢,也有類似 ETL 的批處理,兩者爭用相同資源。傳統數倉體系往往在這兩個方面的兼顧性上做的不夠好。
AnalyticDB worker 接收 coordinator 下發的任務, 負責該任務的物理執行計劃的實際執行。這項任務可以來自不同的查詢, worker 會將任務中的物理執行計劃按照既定的轉換規則轉換成對應的 operator,物理執行計劃中的每一個 Stage 會被轉換成一個或多個 operator。
執行引擎已經可以做到 stage/operator 級別中斷和 Page 級別換入換出,同時線程池在所有同時運行的查詢間共享。但是,這之上仍然需要確保高優先級查詢可以獲得更多計算資源。
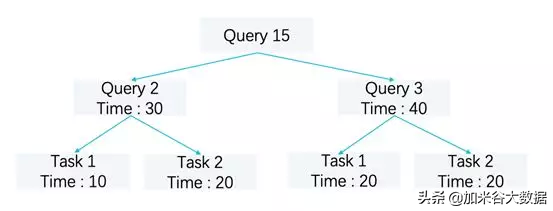
根據經驗,客戶總是期望他們的短查詢即使當系統負載很重的時候也能快速完成。為了滿足這些要求,基于以上場景,通過時間片的分配比例來體現不同查詢的優先級,AnalyticDB 實現了一個簡單版本的類 Linux kernel 的調度算法。系統記錄了每一個查詢的總執行耗時,查詢總耗時又是通過每一個 Task 耗時來進行加權統計的,最終在查詢層面形成了一顆紅黑樹,每次總是挑選最左側節點進行調度,每次取出或者加入(被喚醒以及重新入隊)都會重新更新這棵樹,同樣的,在 Task 被喚醒加入這顆樹的時候,執行引擎考慮了補償機制,即時間片耗時如果遠遠低于其他 Task 的耗時,確保其在整個樹里面的位置,同時也避免了因為長時間的阻塞造成的饑餓,類似于 CFS 調度算法中的 vruntime 補償機制。
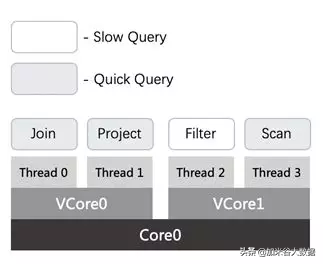
這個設計雖然有效解決了慢查詢占滿資源,導致其他查詢得不到執行的問題,卻無法保障快查詢的請求延遲。這是由于軟件層面的多線程執行機制,線程個數大于了實際的 CPU 個數。在實際的應用中,計算線程的個數往往是可用 Core 的 2 倍。這也就是說,即使快查詢的算子得到了計算線程資源進行計算,也會在 CPU 層面與慢查詢的算子形成競爭。所下圖所示,快查詢的算子計算線程被調度到 VCore1 上,該算子在 VCore1 上會與慢查詢的計算線程形成競爭。另外在物理 Core0 上,也會與 VCore0 上的慢查詢的計算線程形成競爭。
在 Kernel sched 模塊中,對于不同優先級的線程之間的搶占機制,已經比較完善,且時效性比較高。因而,通過引入 kernel 層面的控制可以有效解決快查詢低延遲的問題,且無需對算子的實現進行任何的改造。執行引擎讓高優先級的線程來執行快查詢的算子,低優先級的線程來執行慢查詢的算子。由于高優先級線程搶占低優先級線程的機制,快查詢算子自然會搶占慢查詢的算子。此外,由于高優先級線程在 Kernel sched 模塊調度中,具有較高的優先級,也避免了快慢查詢算子在 vcore 層面的 CPU 競爭。
同樣的在實際應用中是很難要求用戶來辨別快慢查詢,因為用戶的業務本身可能就沒有快慢業務之分。另外對于在線查詢,查詢的計算量也是不可預知的。為此,計算引擎在 Runtime 層面引入了快慢查詢的識別機制,參考 Linux kernel 中 vruntime 的方式,對算子的執行時間、調度次數等信息進行統計,當算子的計算量達到給定的慢查詢的閾值后,會把算子從高優先級的線程轉移到低優先級的線程中。這有效提高了在壓力測試下快查詢的響應時間。
代碼生成器
Dynamic code generation(CodeGen)普遍出現在業界的各大計算引擎設計實現中。它不僅能夠提供靈活的實現,減少代碼開發量,同樣在性能優化方面也有著較多的應用。但是同時基于 ANTLR ASM 的 AnalyticDB 代碼生成器也引入了數十毫秒編譯等待時間,這在實時分析場景中是不可接受的。為了進一步減少這種延遲,分析引擎使用了緩存來重用生成的 Java 字節碼。但是,它并非能對所有情況都起很好作用。
隨著業務的廣泛使用以及對性能的進一步追求,系統針對具體的情況對 CodeGen 做了進一步的優化。使用了 Loading Cache 對已經生成的動態代碼進行緩存,但是 SQL 表達式中往往會出現常量(例如,substr(col1,1, 3),col1 like‘demo%’等),在原始的生成邏輯中會直接生成常量使用。這導致很多相同的方法在遇到不同的常量值時需要生成一整套新的邏輯。這樣在高并發場景下,cache 命中率很低,并且導致 JDK 的 meta 區增長速度較快,更頻繁地觸發 GC,從而導致查詢延遲抖動。
substr(col1, 1, 3)
通過對表達式的常量在生成 bytecode 階段進行 rewrite,對出現的每個常量在 Class 級別生成對應的成員變量來存儲,去掉了 Cachekey 中的常量影響因素,使得可以在不同常量下使用相同的生成代碼。命中的 CodeGen 將在 plan 階段 instance 級別的進行常量賦值。
substr(col1, 1, 3)
在測試與線上場景中,經過優化很多高并發的場景不再出現 meta 區的 GC,這顯著增加了緩存命中率,整體運行穩定性以及平均延遲均有一定的提升。
AnalyticDB CodeGen 不僅實現了謂詞評估,還支持了算子級別運算。例如,在復雜 SQL 且數據量較大的場景下,數據會多次 shuffle 拷貝,在 partitioned shuffle 進行數據拷貝的時候很容易出現 CPU 瓶頸。用于連接和聚合操作的數據 Shuffle 通常會復制從源數據塊到目標數據塊的行,偽代碼如下所示:
foreach row
從生產環境,大部分 SQL 每次 shuffle 的數據量較大,但是列很少。那么首先想到的就是 forloop 的展開。那么上面的偽代碼就可以轉換成
foreach row
上面的優化通過直接編碼是無法完成的,需要根據 SQL 具體的 column 情況動態的生成對應的代碼實現。在測試中 1000w 的數據量級拷貝延時可以提升 24%。
矢量化引擎和二進制數據處理
相對于行式計算,AnalyticDB 的矢量化計算由于對緩存更加友好,并避免了不必要的數據加載,從而擁有了更高的效率。在這之上,AnalyticDB CodeGen 也將運行態因素考慮在內,能夠輕松利用異構硬件的強大功能。例如,在 CPU 支持 AVX-512 指令集的集群,AnalyticDB 可以生成使用 SIMD 的字節碼。同時 AnalyticDB 內部所有計算都是基于二進制數據,而不是 Java Object,有效避免了序列化和反序列化開銷。
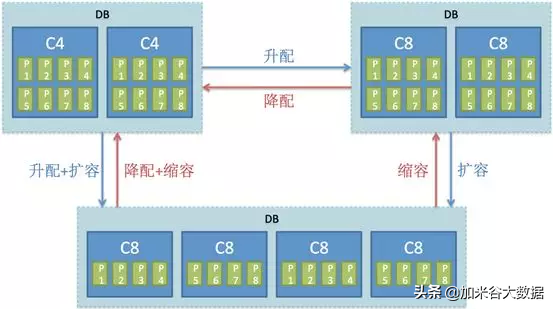
極致彈性
在多租戶基礎上,AnalyticDB 對每個租戶的 DB 支持在線升降配,擴縮容,操作過程中無需停服,對業務幾乎透明。以下圖為例:
用戶開始可以在云上開通包含兩個 C4 資源的 DB 進行業務試用和上線(圖中的 P1, P2…代表表的數據分區)
隨著業務的增長,當兩個 C4 的存儲或計算資源無法滿足時,用戶可自主對該 DB 發起升配或擴容操作,升配 + 擴容可同時進行。該過程會按副本交替進行,保證整個過程中始終有一個副本提供服務。另外,擴容增加節點后,數據會自動在新老節點間進行重分布。
對于臨時性的業務增長(如電商大促),升配擴容操作均可逆,在大促過后,可自主進行降配縮容操作,做到靈活地成本控制。
在線升降配,平滑擴縮容能力,對今年雙十一阿里巴巴集團內和公共云上和電商物流相關的業務庫起到了至關重要的保障作用。
GPU 加速
★ 客戶業務痛點
某客戶數據業務的數據量在半年時間內由不到 200TB 增加到 1PB,并且還在快速翻番,截止到發稿時為止已經超過 1PB。該業務計算復雜,查詢時間跨度周期長,需按照任意選擇屬性過濾,單個查詢計算涉及到的算子包括 20 個以上同時交并差、多表 join、多值列(類似 array)group by 等以及上述算子的各種復雜組合。傳統的 MapReduce 離線分析方案時效性差,極大限制了用戶快速分析、快速鎖定人群并即時投放廣告的訴求,業務發展面臨新的瓶頸。
★ AnalyticDB 加速方案
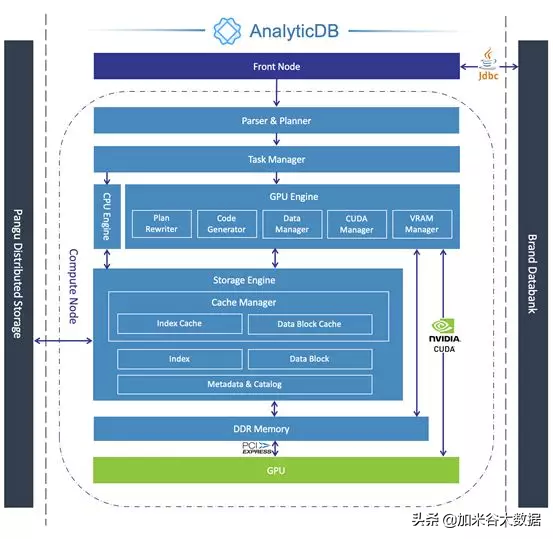
GPU 加速 AnalyticDB 的做法是在 Compute Node 中新增 GPU Engine 對查詢進行加速。GPU Engine 主要包括: Plan Rewriter、Task Manager、Code Generator、CUDA Manager、Data Manager 和 VRAM Manager。
SQL 查詢從 Front Node 發送到 Compute Node,經過解析和邏輯計劃生成以后,Task Manager 先根據計算的數據量以及查詢特征選擇由 CPU Engine 還是 GPU Engine 來處理,然后根據邏輯計劃生成適合 GPU 執行的物理計劃。
GPU Engine 收到物理計劃后先對執行計劃進行重寫。如果計劃符合融合特征,其中多個算子會被融合成單個復合算子,從而大量減少算子間臨時數據的 Buffer 傳輸。
Rewriting 之后物理計劃進入 Code Generator,該模塊主功能是將物理計劃編譯成 PTX 代碼。Code Generator 第一步借助 LLVM JIT 先將物理計劃編譯成 LLVM IR,IR 經過優化以后通過 LLVMNVPTX Target 轉換成 PTX 代碼。CUDA 運行時庫會根據指定的 GPU 架構型號將 PTX 轉換成本地可執行代碼,并啟動其中的 GPU kernel。Code Generator 可以支持不同的 Nvidia GPU。
CUDA Manager 通過 jCUDA 調用 CUDA API,用于管理和配置 GPU 設備、GPU kernel 的啟動接口封裝。該模塊作為 Java 和 GPU 之間的橋梁,使得 JVM 可以很方便地調用 GPU 資源。
Data Manager 主要負責數據加載,將數據從磁盤或文件系統緩存加載到指定堆外內存,從堆外內存加載到顯存。CPU Engine 的執行模型是數據庫經典的火山模型,即表數據需逐行被拉取再計算。這種模型明顯會極大閑置 GPU 上萬行的高吞吐能力。目前 Data Manager 能夠批量加載列式數據塊,每次加載的數據塊大小為 256M,然后通過 PCIe 總線傳至顯存。
VRAM Manager 用于管理各 GPU 的顯存。顯存是 GPU 中最稀缺的資源,需要合理管理和高效復用,有別于現在市面上其他 GPU 數據庫系統使用 GPU 的方式,即每個 SQL 任務獨占所有的 GPU 及其計算和顯存資源。為了提升顯存的利用率、提升并發能力,結合 AnalyticDB 多分區、多線程的特點,我們設計基于 Slab 的 VRAM Manager 統一管理所有顯存申請:Compute Node 啟動時,VRAM Manager 先申請所需空間并切分成固定大小的 Slab,這樣可以避免運行時申請帶來的時間開銷,也降低通過顯卡驅動頻繁分配顯存的 DoS 風險。
在需要顯存時,VRAM Manager 會從空閑的 Slab 中查找空閑區域劃分顯存,用完后返還 Slab 并做 Buddy 合并以減少顯存空洞。性能測試顯示分配時間平均為 1ms,對于整體運行時間而言可忽略不計,明顯快于 DDR 內存分配的 700ms 耗時,也利于提高系統整體并發度。在 GPU 和 CPU 數據交互時,自維護的 JVM 堆外內存會作為 JVM 內部數據對象(如 ByteBuffer)和顯存數據的同步緩沖區,也一定程度減少了 Full GC 的工作量。
GPU Engine 采用即時代碼生成技術主要有如下優點:
相對傳統火山模型,減少計劃執行中的函數調用等,尤其是分支判斷,GPU 中分支跳轉會降低執行性能
靈活支持各種復雜表達式, 例如 projection 和 having 中的復雜表達式。例如 HAVING SUM(double_field_foo) > 1 這種表達式的 GPU 代碼是即時生成的
靈活支持各種數據類型和 UDF 查詢時追加
利于算子融合,如 group-by 聚合、join 再加聚合的融合,即可減少中間結果(特別是 Join 的連接結果)的拷貝和顯存的占用
根據邏輯執行計劃動態生成 GPU 執行碼的整個過程如下所示:
★ GPU 加速實際效果
該客戶數據業務使用了 GPU 實時加速后,將計算復雜、響應時間要求高、并發需求高的查詢從離線分析系統切換至 AnalyticDB 進行在線分析運行穩定,MapReduce 離線分析的平均響應時間為 5 到 10 分鐘,高峰時可能需要 30 分鐘以上。無縫升級到 GPU 加速版 AnalyticDB 之后,所有查詢完全實時處理并保證秒級返回,其中 80% 的查詢的響應時間在 2 秒以內(如下圖),而節點規模降至原 CPU 集群的三分之一左右。 業務目前可以隨時嘗試各種圈人標簽組合快速對人群畫像,即時鎖定廣告投放目標。據客戶方反饋,此加速技術已經幫助其在競爭中構建起高壁壘,使該業務成為同類業務的核心能力,預計明年用戶量有望翻番近一個數量級。
總結
簡單對本文做個總結,AnalyticDB 做到讓數據價值在線化的核心技術可歸納為:
高性能 SQL Parser:自研 Parser 組件 FastSQL,極致的解析性能,無縫集合優化器
玄武存儲引擎:數據更新實時可見,行列混存,粗糙集過濾,聚簇列,索引優化
羲和計算引擎:MPP+DAG 融合計算,CBO 優化,向量化執行,GPU 加速
極致彈性:業務透明的在線升降配,擴縮容,靈活控制成本。
GPU 加速:利用 GPU 硬件加速 OLAP 分析,大幅度降低查詢延時。
分析型數據 AnalyticDB, 作為阿里巴巴自研的下一代 PB 級實時數據倉庫, 承載著整個集團內和云上客戶的數據價值實時化分析的使命。 AnalyticDB 為數據價值在線化而生,作為實時云數據倉庫平臺,接下來會在體驗和周邊生態建設上繼續加快建設,希望能將最領先的下一代實時分析技術能力普惠給所有企業,幫助企業轉型加速數據價值探索和在線化。
聲明:本文由網站用戶竹子發表,超夢電商平臺僅提供信息存儲服務,版權歸原作者所有。若發現本站文章存在版權問題,如發現文章、圖片等侵權行為,請聯系我們刪除。